
数日前、LinuxAdictos の友人が、PDF ファイルを自動またはほぼ自動的に EPUB に変換する方法に関するチュートリアルを公開しました。このチュートリアルは非常によくできていますが、初心者がそれを実行したり従うのは難しいかもしれません。そのため、このチュートリアルの第 2 バージョンを提供し、ダミー向けに改良して説明しました。
まず、PDF ファイルを Epub に変換するには、コンピューターに Caliber がインストールされている必要があります。まだインストールされていない場合は、これを確認してください。 リンク 方法が説明されている場所。 インストールしたら、«本を追加»(左上隅にあります) 変換したい pdf を追加します。 PDFファイルを追加したら、それをマークしてボタンを押します«本を変換する»その後、Epubに提供したいオプションを設定するための画面が表示されます.
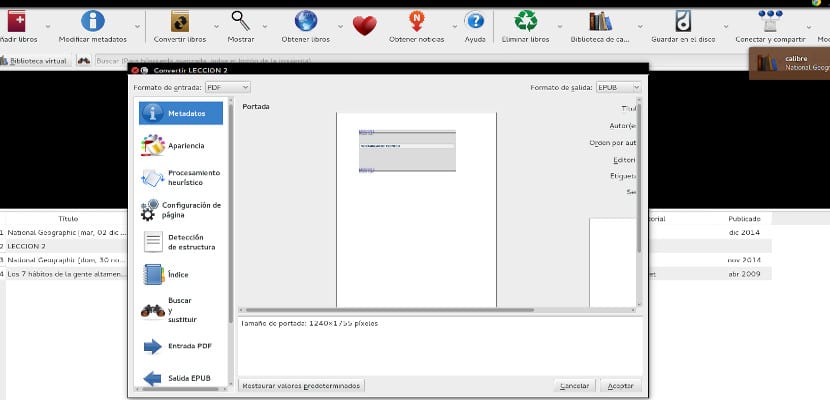
その画面の XNUMX つの上部隅に XNUMX つのタブがあり、XNUMX つは入力形式を示し、もう XNUMX つは出力形式を示します。 入力形式では«PDF»のままにして、出力形式では«EPUB»が表示されるようにします。
Caliber を使用すると、pdf ファイルをほぼすべての形式に変換できます。
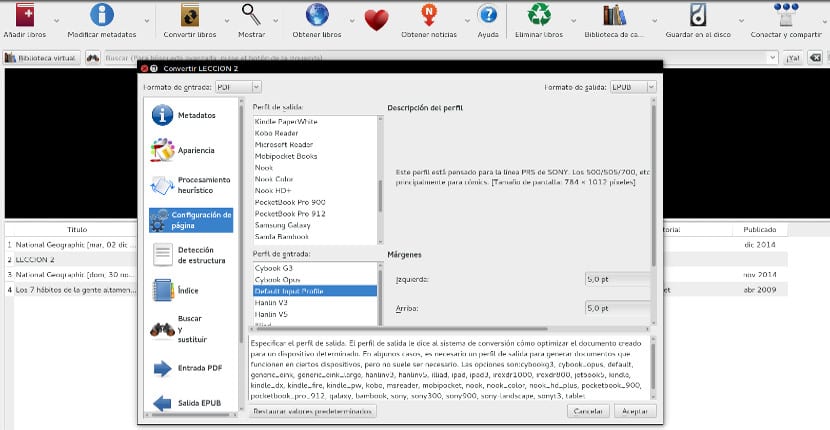
これで、下部に表示される「同意する」ボタンを押すか、横にあるさまざまなアイコンを使用してオプションをカスタマイズできます。 これらのオプションはさまざまで、非常に興味深いものです。 個人的には、インデックスの追加、フォントのカスタマイズ、表紙などをお勧めします... 存在する最も重要なオプションの XNUMX つは「ページ設定」オプションです。 EPUBシート。 したがって、Epub を最適化するかどうかを選択できます タブレット、Kindle Paperwhite、Koboなど...
そしてもちろん、メタデータ (上からの最初のオプション) を変更して、電子ブックを好みに合わせて分類できるだけでなく、他のライブラリにエクスポートできるようにします。
データのカスタマイズが完了したら、[同意する] をクリックすると、Caliber が PDF の Epub ファイルを作成します。 ご覧のとおり、これは非常に便利で使いやすいツールです。今は作業に取り掛かり、pdf ファイルを変換するだけです。
PDF から epub (または txt など) に変換できるのと同じように、変換には損失が伴うことに注意してください。 問題は、PDF が印刷を目的とした形式であり、ページ上の位置を含む文字と記号のセットが保存されることです。 さあ、PDFに変換すると行、段落などの情報がすべて失われるので、もう一度取得したい場合は「推測」する必要があります。 そして、そのプロセスは簡単ではなく、正確でもありません。 再構築できるものはたくさんありますが、そうでない情報もあるので、変換は決して完全ではありません。
類似点は、画像の OCRing と同じです。 はい、可能であり、JPEG から DOC を生成することを約束する多くのプログラムがありますが、変換は完全ではありません。 したがって、はい、PDF を epub に変換することはできますが、それを回避して「ネイティブ」の epub を直接使用することができれば、さらに良いでしょう。 カットされた段落や、キャリッジからピニオンへの戻りがあるため画面に収まらないテキスト、およびその他の多くの副作用は避けます。
昨日、pdfを変換しようとしました。 Epub に変換しましたが、変換がうまくいきませんでした。段落がすべて間違っていました。
そして最悪なのは、誰もその問題の解決策を提供していないということです。